һ�б������(g��)ID��������(g��)�ö�̖(h��o)���_��ID�D(zhu��n)�Q���ö�̖(h��o)���_�����Q��_Mssql��(sh��)��(j��)��(k��)�̳�
���]����(j��ng)��SQL�Z(y��)���ȫһ�����A(ch��) 1���f(shu��)������(chu��ng)����(sh��)��(j��)��(k��) CREATE DATABASE database - name 2���f(shu��)�����h����(sh��)��(j��)��(k��) drop database dbname 3���f(shu��)�������sql server -- - ��(chu��ng)�� ��ݔ�(sh��)��(j��)�� device USE master EXEC sp_addumpdevice ' disk ' , ' testBack ' , ' c:\mssql7backup\MyNwind_1.dat ' --
�����������(xi��ng)Ŀ�r(sh��)����(j��ng)����(hu��)�����@�ӵı��Y(ji��)��(g��u)������������һ�б�������ö�̖(h��o)���_ID���磬��(d��ng)һ��(g��)�T���Čٶ���(g��)���T�r(sh��)����(d��ng)һ��(g��)�(xi��ng)Ŀ�Čٶ���(g��)���Еr(sh��)����(d��ng)һ��(g��)�O(sh��)��Čٶ���(g��)�(xi��ng)Ŀ�r(sh��)���ܶ��˶���(hu��)�چT�����м���һ��(g��)deptIds VARCHAR(1000)�У������ԆT���Čٶ���(g��)���T�����������Ա��沿�T��̖(h��o)�б��������@�@�����ϵ�һ��ʽ�����ܶ����@���O(sh��)Ӌ(j��)�ˣ����@ƪ�������҂�����ӑՓ���@�N��(y��ng)�È�(ch��ng)���£�����O(sh��)Ӌ(j��)�Č�(du��)�c�e(cu��)�����dȤ�Ŀ����ڻ؏�(f��)�����ģ���Ȼ���҂�?c��)ڲ�ԃ�б�����Ҫ�����@��(g��)�T���Č���Щ���T����ʼ����(sh��)��(j��)��
���T�����T���픵(sh��)��(j��)��
- IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Department]'))
- DROP TABLE [dbo].Department
- GO
- --���T��
- CREATE TABLE Department
- (
- id int,
- name nvarchar(50)
- )
- INSERT INTO Department(id,name)
- SELECT 1,'���²�'
- UNION
- SELECT 2,'���̲�'
- UNION
- SELECT 3,'������'
- SELECT * FROM Department
- IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Employee]'))
- DROP TABLE [dbo].Employee
- GO
- --�T����
- CREATE TABLE Employee
- (
- id int,
- name nvarchar(20),
- deptIds varchar(1000)
- )
- INSERT INTO Employee(id,name,deptIds)
- SELECT 1,'�Y���A','1,2,3'
- UNION
- SELECT 2,'��','1'
- UNION
- SELECT 3,'С�A',''
- SELECT * FROM Employee
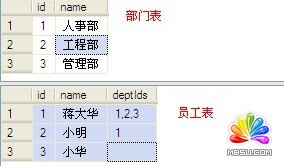
ϣ���õ��ĽY(ji��)����

��Q������
��һ�����ǵõ����µĔ�(sh��)��(j��)�������T���������c���P(gu��n)�IJ��T�����������B�ӣ�����ʹ����fun_SplitIds����(sh��)�������nj�ids�ָ��id�б�����Ȼ��T�������c�@��(g��)�õ��ļ����������B��
SELECT E.*,ISNULL(D.name,'') AS deptName FROM Employee AS E OUTER APPLY dbo.fun_SplitIds(E.deptIds) AS DID LEFT JOIN Department AS D ON DID.ID=D.id;

�ڶ������ѽ�(j��ng)�õ������ϵĔ�(sh��)��(j��)��Ȼ��Ҫ���ľ��Ǹ���(j��)ID�ֽM������(du��)deptName�����ۺϲ���������ϧ����SQL SERVER߀�]���ṩ��(du��)�ַ������ۺϵIJ��������뵽���҂�̎����νY(ji��)��(g��u)��(sh��)��(j��)�r(sh��)����CTE��(l��i)���P(gu��n)ϵ��(sh��)��(j��)�������И��θ�ʽ�Ĕ�(sh��)��(j��)������҂�Ҳ���Ԍ��@��(g��)��(w��n)�}�D(zhu��n)�Q�������θ�ʽ�Ć�(w��n)�}�����a���£�
�Y(ji��)�����£�
- WITH EmployeT AS(
- --�T���Ļ�����Ϣ(ʹ��OUTER APPLY������(g��)ID����_��(l��i),Ȼ���c���T�����P(gu��n)(li��n))
- --�˕r(sh��)�ь��T���������IDS�քe�c���T���P(gu��n)(li��n),������Ҫ���˼����е�deptName�ۺϳ�һ��(g��)ӛ�
- SELECT E.*,ISNULL(D.name,'') AS deptName
- FROM Employee AS E
- OUTER APPLY dbo.fun_SplitIds(E.deptIds) AS DID
- LEFT JOIN Department AS D ON DID.ID=D.id
- ),mike AS(
- SELECT id,name,deptIds,deptName
- ,ROW_NUMBER()OVER(PARTITION BY id ORDER BY id) AS level_num
- FROM EmployeT
- ),mike2 AS(
- SELECT id,name,deptIds,CAST(deptName AS NVARCHAR(100)) AS deptName,level_num
- FROM mike
- WHERE level_num=1
- UNION ALL
- SELECT m.id,m.name,m.deptIds,CAST(m2.deptName+','+m.deptName AS NVARCHAR(100)) AS deptName,m.level_num
- FROM mike AS m
- INNER JOIN mike2 AS m2 ON m.ID=m2.id AND m.level_num=m2.level_num+1
- ),maxMikeByIDT AS(
- SELECT id,MAX(level_num) AS level_num
- FROM mike2
- GROUP BY ID
- )
- SELECT A.id,A.name,A.deptIds,A.deptName
- FROM mike2 AS A
- INNER JOIN maxMikeByIDT AS B ON A.id=B.ID AND A.level_num=B.level_num
- ORDER BY A.id OPTION (MAXRECURSION 0)
ȫ��SQL��
- IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Department]'))
- DROP TABLE [dbo].Department
- GO
- --���T��
- CREATE TABLE Department
- (
- id int,
- name nvarchar(50)
- )
- INSERT INTO Department(id,name)
- SELECT 1,'���²�'
- UNION
- SELECT 2,'���̲�'
- UNION
- SELECT 3,'������'
- SELECT * FROM Department
- IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Employee]'))
- DROP TABLE [dbo].Employee
- GO
- --�T����
- CREATE TABLE Employee
- (
- id int,
- name nvarchar(20),
- deptIds varchar(1000)
- )
- INSERT INTO Employee(id,name,deptIds)
- SELECT 1,'�Y���A','1,2,3'
- UNION
- SELECT 2,'��','1'
- UNION
- SELECT 3,'С�A',''
- SELECT * FROM Employee
- --��(chu��ng)��һ��(g��)��ֵ����(sh��)���Á�(l��i)����ö�̖(h��o)�ָ�Ĕ�(sh��)�ִ�������ֻ��һ�Д�(sh��)�ֵı�
- IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[fun_SplitIds]'))
- DROP FUNCTION [dbo].fun_SplitIds
- GO
- CREATE FUNCTION dbo.fun_SplitIds(
- @Ids nvarchar(1000)
- )
- RETURNS @t_id TABLE (id VARCHAR(36))
- AS
- BEGIN
- DECLARE @i INT,@j INT,@l INT,@v VARCHAR(36);
- SET @i = 0;
- SET @j = 0;
- SET @l = len(@Ids);
- while(@j < @l)
- begin
- SET @j = charindex(',',@Ids,@i+1);
- IF(@j = 0) set @j = @l+1;
- SET @v = cast(SUBSTRING(@Ids,@i+1,@j-@i-1) as VARCHAR(36));
- INSERT INTO @t_id VALUES(@v)
- SET @i = @j;
- END
- RETURN;
- END
- GO
- ;WITH EmployeT AS(
- --�T���Ļ�����Ϣ(ʹ��OUTER APPLY������(g��)ID����_��(l��i),Ȼ���c���T�����P(gu��n)(li��n))
- --�˕r(sh��)�ь��T���������IDS�քe�c���T���P(gu��n)(li��n),������Ҫ���˼����е�deptName�ۺϳ�һ��(g��)ӛ�
- SELECT E.*,ISNULL(D.name,'') AS deptName
- FROM Employee AS E
- OUTER APPLY dbo.fun_SplitIds(E.deptIds) AS DID
- LEFT JOIN Department AS D ON DID.ID=D.id
- ),mike AS(
- SELECT id,name,deptIds,deptName
- ,ROW_NUMBER()OVER(PARTITION BY id ORDER BY id) AS level_num
- FROM EmployeT
- ),mike2 AS(
- SELECT id,name,deptIds,CAST(deptName AS NVARCHAR(100)) AS deptName,level_num
- FROM mike
- WHERE level_num=1
- UNION ALL
- SELECT m.id,m.name,m.deptIds,CAST(m2.deptName+','+m.deptName AS NVARCHAR(100)) AS deptName,m.level_num
- FROM mike AS m
- INNER JOIN mike2 AS m2 ON m.ID=m2.id AND m.level_num=m2.level_num+1
- ),maxMikeByIDT AS(
- SELECT id,MAX(level_num) AS level_num
- FROM mike2
- GROUP BY ID
- )
- SELECT A.id,A.name,A.deptIds,A.deptName
- FROM mike2 AS A
- INNER JOIN maxMikeByIDT AS B ON A.id=B.ID AND A.level_num=B.level_num
- ORDER BY A.id OPTION (MAXRECURSION 0)
������SQL Server�ַ����и��Y(ji��)���� 645002*01 --1 45854 --2 183677
- sql �Z(y��)�侚��(x��)�c��
- ����C++ string.find()����(sh��)���÷����Y(ji��)
- SQL Server�Єh���؏�(f��)��(sh��)��(j��)�Ďׂ�(g��)����
- sql�h���؏�(f��)��(sh��)��(j��)��Ԕ��(x��)����
- SQL SERVER 2000���b�̳̈D��Ԕ��
- ʹ��sql server management studio 2008 �o(w��)���鿴��(sh��)��(j��)��(k��),��ʾ �o(w��)����ԓՈ(q��ng)��z����(sh��)��(j��) �e(cu��)�`916��Q����
- SQLServer��־����Z(y��)��(sql2000,sql2005,sql2008)
- Sql Server 2008��ȫж�d����(�����汾���)
- sql server 2008 �����S������ģ��������ĸ���Ҫ��h��������(chu��ng)�����±�
- SQL Server 2008 ��Մh����־�ļ�(˲�g��־׃��M)
- Win7ϵ�y(t��ng)���bMySQL5.5.21�D��̳�
- ��DataTable����惦(ch��)�^(gu��)�̅���(sh��)���÷���(sh��)��Ԕ��
Mssql��(sh��)��(j��)��(k��)�̳�Rssӆ����̳̽�����
Mssql��(sh��)��(j��)��(k��)�̳����]
- ���Y(ji��)��(j��ng)�䳣�õ�SQL�Z(y��)��(1)
- SQL Serverռ�Ã�(n��i)��Ľ�Q����
- ��SQL Server HavingӋ(j��)���к�ƽ��ֵ
- Ԕ��Windows Server 2008�е�NAP
- ����SQL Server��(sh��)��(j��)��(k��)�|�l(f��)����ȫ�[��
- ��������Ҏ(gu��)��ʹ��Oracle��(sh��)��(j��)���g
- SQL Server �������A(ch��)֪�R(sh��)(4)----���I�c�ۼ�����
- Sql�Z(y��)���ܴa�(y��n)�C�İ�ȫ©��
- ��DataTable����惦(ch��)�^(gu��)�̅���(sh��)���÷���(sh��)��Ԕ��
- SQL Server 2005��ӹ��ߺ��\(y��n)�Еr(sh��)�g��
����Ҳϲ�g���@Щ
- mysql�e(cu��)�`����Qȫ����
- mysql��text�cvarchar�cchar�ą^(q��)�e
- MySQL�Pӛ֮������ʹ��
- MySQL���F(xi��n)����unauthenticated user
- MySQL��ԃ��(y��u)��:���Ӳ�ԃ��������I�B�Ӳ�ԃ��(sh��)����B
- mysql ���r(sh��)���±��ֶ��е�ֵ��B(t��i)
- MySQL��(sh��)��(j��)��(k��)INNODB ��?y��)p���ޏ�(f��)�^(gu��)��
- java�B��mysql��(sh��)��(j��)��(k��)�y�a��ô�k
- MySQL�Pӛ֮�B�Ӳ�ԃ?c��)��?/a>
- ����Xtrabackup���߂�ݼ��֏�(f��)(MySQL DBA�ı乤��)
- ���P(gu��n)朽ӣ�
��(f��)�Ʊ��(y��)朽�| ����һ�б������(g��)ID��������(g��)�ö�̖(h��o)���_��ID�D(zhu��n)�Q���ö�̖(h��o)���_�����Q��
- �̳��f(shu��)����
Mssql��(sh��)��(j��)��(k��)�̳�-һ�б������(g��)ID��������(g��)�ö�̖(h��o)���_��ID�D(zhu��n)�Q���ö�̖(h��o)���_�����Q��
 ��
��